Florian Vogt
Hej! I am a Research Engineer at KTH Royal Institute of Technology in Stockholm, where I develop reinforcement learning algorithms for challenging real-world problems in robotics simulations.
I received my Master's degree from the University of Freiburg. My research lies at the intersection of machine learning and systems, with a focus on making reinforcement learning more sample-efficient, computationally efficient, and scalable.
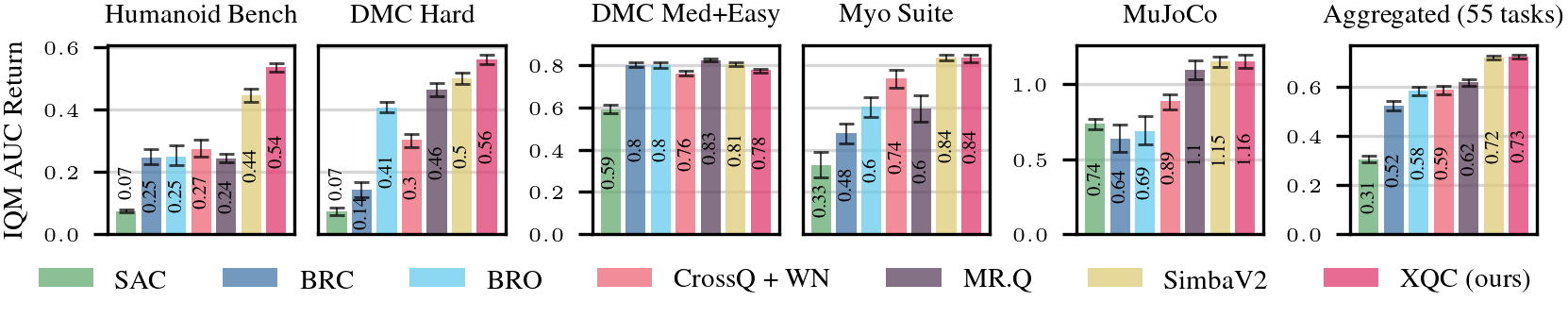
I am particularly interested in developing simple, efficient algorithms that scale to challenging reinforcement learning problems. This work has led to XQC, a simple yet effective optimization method for off-policy reinforcement learning, whose ideas were later incorporated into FlashSAC, recipient of the RSS 2026 Outstanding Paper Award.